





An electrocardiogram (ECG) is a quintessential weapon in the arsenal of a cardiologist to detect abnormalities of the heart. As the heart expands and contracts it gives off electrical pulses. The ECG machine, called an electrocardiograph, detects these electrical pulses and traces them as a wave on a graph sheet – this graph is called an electrocardiogram (ECG). When the heart is functioning normally the ECG has a characteristic morphology which is a gestalt of multiple features that to the trained eye may be considered normal. Abnormalities within any of these cardinal attributes may suggest underlying pathology of the heart’s circuitry, muscle or structure.
Electrocardiographs are not expensive and readily available, but unfortunately, a cardiologist-level training or experience with ECG interpretation is required to effectively read ECGs. While there are automated diagnostics built in to most ECG machines, they seem to have heterogeneous accuracy and are never relied upon in a clinical setting. We believe access to the right information can help medical professionals make the right decisions at crucial junctures. For instance, having access to an autonomous ECG-diagnosis system with cardiologist-level accuracy in scenarios where paramedics are responding to a chest pain, or handling medical emergencies in rural Australia could have a huge societal impact.
The AI for Society (AIFS) collective, in collaboration with Hessian AI Labs is working with the cardiology department at Campbelltown Hospital to design a neural network based automated ECG diagnosis system. Our goal is to build an Artificial Intelligence (AI) system that can provide quick diagnosis with cardiologist-level accuracy.
ECG Classifier
Building any AI system involves training a machine learning model with vast troves of data so it can learn patterns in the existing data and predict outcomes for new data points. Before moving directly to a complex system that can do ECG-based diagnosis, we aimed to start small by creating a system that can distinguish between normal and abnormal ECGs. We believed this would also get us exposed to the potential issues and challenges of tackling this task. Our initial approach showed promise, but after taking stock of the data inventory at Campbelltown hospital, it was quickly evident that we lacked enough de-identified labelled ECGs to leverage machine learning models such as Convolutional Neural Networks. Data is the oil for any machine learning model, and the lack of data was really hurting the quality of the outcome and its accuracy. Therefore, it was clear that we needed a two pronged approach to solve this problem:
- Get more data to train the model by setting up data aggregation infrastructure that can collect, de-identify, label, and store the ECGs in a secure and automated manner.
- Use pre-trained models to reduce the amount of data required (sample complexity) to train the ECG classifier.
Data Aggregation
One of the major challenges with machine learning projects today is the lack of availability of the right set of data that can be used to train models. Machine learning models can make predictions, but they first need to learn the underlying patterns from existing data to be able to effectively discriminate. Hospitals have a lot of ECG samples, but they are scattered across various departments, and usually not labelled as Normal/Abnormal before being stored. Manually labelling all of the existing data is not feasible as it is tedious, time consuming, and requires cardiologists to spend a lot time they don’t have. So getting access to labelled ECG data was proving to be a challenge.
The other requirement before using actual data to train the machine learning model is to de-identify the data by removing any patient identifiable information. Manual de-identification is again a tedious and time-consuming task. Since 12 lead ECGs more or less subscribe to a fixed format, this task was easily automated with a programmatic approach.
To make the whole process of acquiring data seamless and consistent, we endeavoured to create a customisable and reusable Data Aggregation framework that can be deployed at hospitals to collect, de- identify, label, and store any medical data such as ECG, Xray, Echocardiogram, Cardiac Electrophysiology dataset etc. Since the capability of any AI system is directly proportional to the quality of the dataset the system consumes, it was paramount to have the data aggregation infrastructure in place.
Data Aggregation Framework
Digital copies of the 12 lead ECG flows into a restricted access ECG database via networked data pipelines from various clinical services such as cardiac diagnostic unit, coronary care unit, emergency department and electrophysiology laboratory. The ECGs are de-identified to preserve patient confidentiality, and those with a Medical Record Number (MRN) go through an extra encryption process to retain the MRN information. The de-identified dataset is consumed by the current gold standard for labelling, a consortium of cardiologists. To be mindful that a cardiologists time is valuable we plan to provide a labelling interface through both mobile and desktop. As the labelling process picks up pace the system intelligently prompts the cardiologists with probable diagnoses, thereby allowing cardiologists to spend lesser time choosing the correct diagnosis.
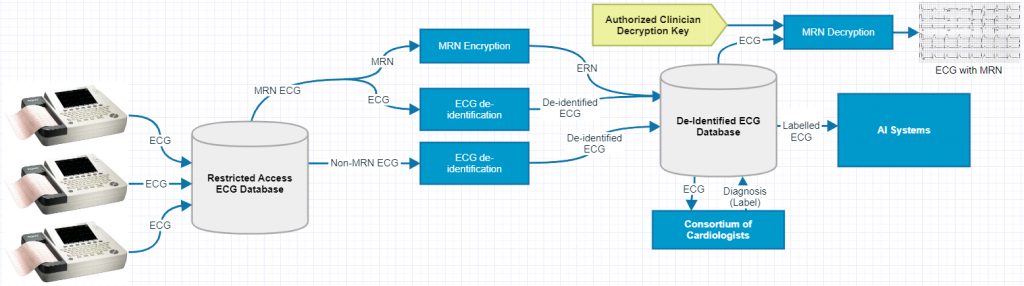
In essence, the data aggregation process would lay the foundations for future projects that require structured and labelled data. The project is currently being prepared to be submitted for ethics consideration at the Campbelltown hospital.
Pre-trained model design
More data is always a boon when developing AI systems. That said, getting the same efficiency with lesser data is even better. A neural network based ECG classifier looks at data to find patterns that allows it to discriminate between abnormal and normal ECGs. Neural networks learn patterns in a hierarchical manner, first they learn primitive features like lines, edges, corners etc, then they learn higher-order combination features like peaks, valleys, slope etc. Informally, we can say that as the neural network trains, it gains an understanding as to what an ECG looks like.
One problem with this training regimen of neural networks is that, for new tasks, it is not designed to utilize the learnings from networks that were trained on similar domains; the network has to re-learn even the primitive features from scratch. To avoid this pitfall, we leverage a technique called transfer learning where we use pre-trained models that have been trained on large and easily accessible datasets. However, while various pre-trained models are available for common computer-vision tasks, when it comes to the medical field the quality and quantity of existing pre-trained models is lacking.
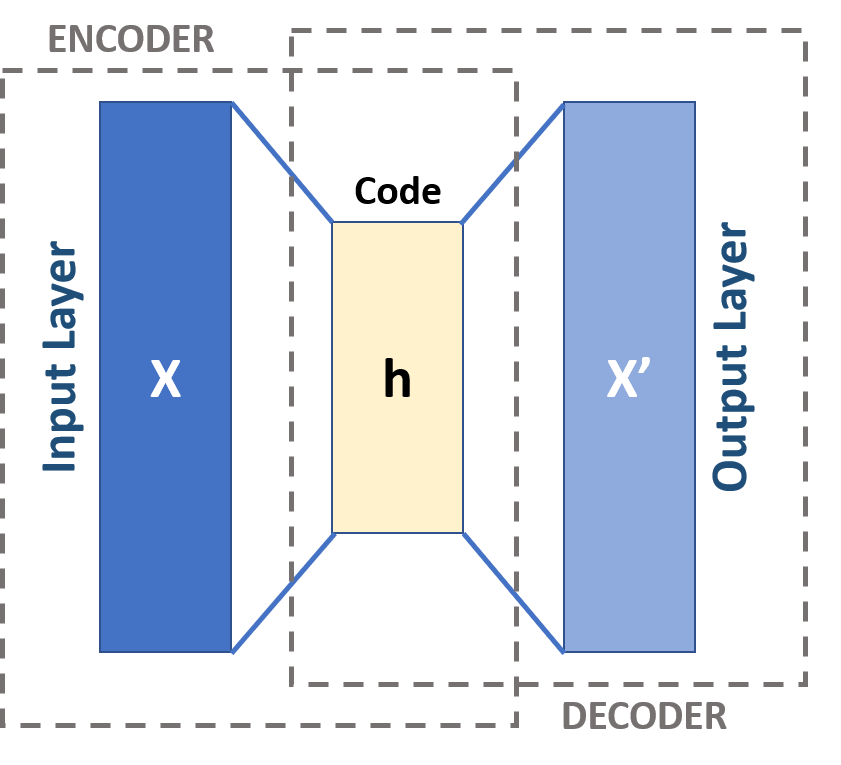
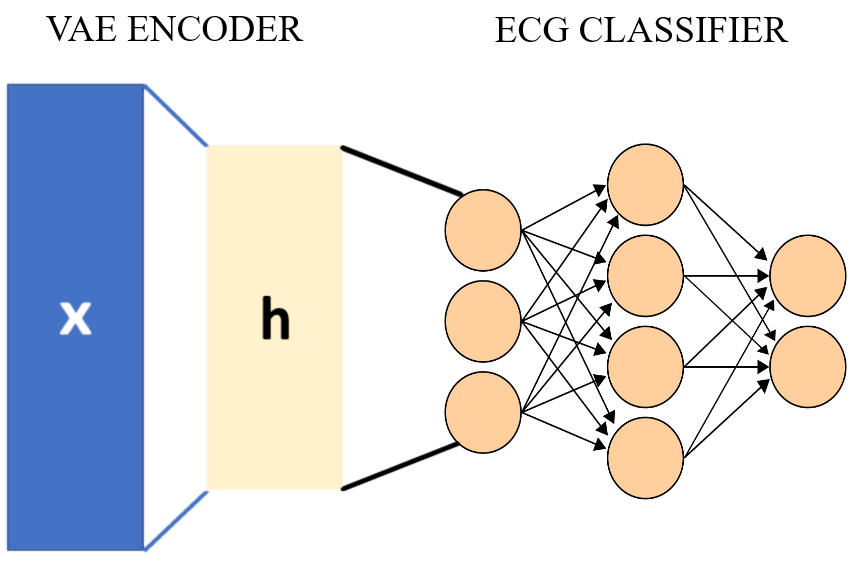
To train our ECG classifier in a data-efficient manner we need a pre-trained model that understands the basic features of an ECG, which means that we need a model that is “pre-trained” on ECG data. As an initial proof of concept (POC) we created our own pre-trained model using a neural network architecture called Variational Autoencoders (VAE). The VAE has two parts, an encoder and a decoder as shown in the image below. The encoder network compresses the input ECG image into a code and then the decoder decompresses the code to reconstruct the original image. Simply put, the network is trained so that the network minimizes the reconstruction error: (x'-x).
In our POC, we trained a VAE model with close to 92 million adaptable parameters with 8500 ECGs. Even though 8500 data points is not something to brag about when dealing with Deep Neural Networks, we got a fairly good reconstruction of the ECG (see image below).
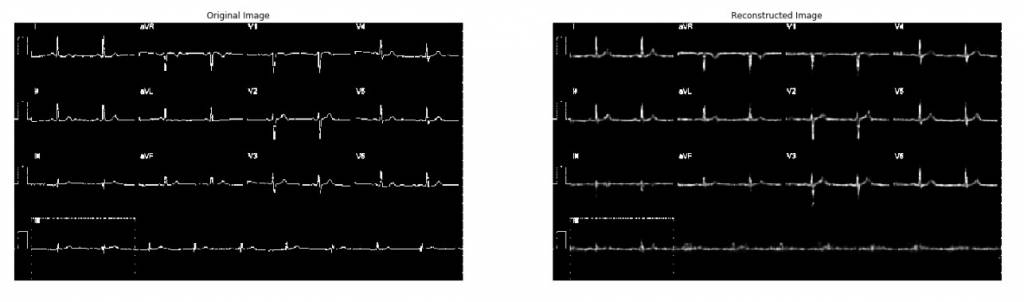
Once the ECG data across the hospital is aggregated, we plan to train a larger VAE network that can handle higher resolution, and at the same time achieve better reconstruction error.
Encoder as a pre-trained model
Compression is analogous to pattern recognition, which means that if you can find some pattern within data, we can exploit that pattern to perform compression. In this sense, the encoder of the VAE is doing just that, finding patterns in a hierarchical manner within a dataset of ECGs. Once our VAE is trained to sufficient accuracy, we can leverage the encoder part of the trained VAE as a pre-trained network for our ECG classifier.
Generative Modeling
Recently, researchers have been able to generate faces of people that do not exist, but look real and lifelike. Such methods for creating synthetic (computer generated) data that very accurately mimic the features of the original dataset is called Generative Modelling. Apart from being a compressor, the Variational Autoencoder (VAE) architecture that we used to pre-train our ECG classifier is also a generative model. Therefore, a VAE trained on an ECG dataset allows us to create purely synthetic ECGs that has most of the properties of an ECG. Below we show an animation of how the VAE generates a synthetic ECGs during the training phase.

One application for such a technology is to generate ECGs that exhibit a certain morbidity. An ECG dataset generated in such a manner can then be utilized by medical students to test their diagnostic capability.
Current Status
The proliferation of AI in healthcare is very low and slow. The main reason for this is the bottleneck of getting patient-data out from hospitals and into the hands of data scientists. Unfortunately, this “bottleneck” is essential to prevent patient identifiable information from falling into the wrong hands. The only way to solve this impasse is to setup automated data aggregation processes that guarantee patient privacy and has a rigorous ethical oversight. Our project is currently being prepared for ethics considerations to start data collection at the Campbelltown Hospital to resonate with this ethos.